

")








Speech recognition technology in radiology
- Authors: Kudryavtsev N.D.1, Bardasova K.A.2, Khoruzhaya A.N.1
-
Affiliations:
- Moscow Center for Diagnostics and Telemedicine
- Ural State Medical University
- Issue: Vol 4, No 2 (2023)
- Pages: 185-196
- Section: Reviews
- Submitted: 17.03.2023
- Accepted: 19.04.2023
- Published: 12.07.2023
- URL: https://jdigitaldiagnostics.com/DD/article/view/321420
- DOI: https://doi.org/10.17816/DD321420
- ID: 321420

Cite item

Abstract
Speech recognition devices are promising tools for the healthcare system. Speech recognition technology has had a relatively long history of use in Western healthcare systems since the 1970s. However, it became widely used at the beginning of the 21st century, replacing medical transcriptionists. This technology is relatively new in home healthcare. Its active development began only in the early 2010s, and its implementation in healthcare started in late 2010. This delay is due to the idiosyncrasies of the Russian language and the limited computational power present at the beginning of the 21st century.
Currently, complexes of devices and software for speech recognition are used in the voice filling of medical records and can reduce the time for preparing reports for radiological examinations compared with traditional (keyboard) text input.
The literature review provides a brief history of speech recognition technology development and application in radiography. Key scientific studies showing its efficacy in Western healthcare systems are reflected. Voice recognition technology in the home is demonstrated, and its effectiveness is evaluated. The prospects for further development of this technology in Russian healthcare are described.
Full Text
INTRODUCTION
At present, voice control has become a standard feature for many home smart devices. This was made possible by the development of speech recognition technology (SRT), which can be used in systems analyzing and transforming the user’s speech into digital data. Furthermore, to controlling smart devices, SRT has become very popular in telephone communications. Currently, when calling many government and commercial organizations, the user is met by an automatic responding machine that recognizes the caller’s voice request and refers them to a selected specialist. In 2019, in Moscow, a project was launched to notify citizens of an appointment with a doctor and remind them of regular check-up using a voice assistant. During a call, the citizen could make an appointment with a medical specialist, cancel, or reschedule the visit, and the system also asked the patient about complaints.1
In healthcare, SRT systems are actively used in the voice filling of medical records. This is because healthcare professionals spend most of their working time preparing medical documentation [1–4]. This factor negatively affects the quality of medical care, particularly considering the limited duration of appointments for each patient. Opportunities for using this technology, for example, in diagnostic radiology, are associated with decreased time spent filling out protocols for diagnostic examinations and increased time analyzing diagnostic images and medical records and communicating with patients. Thus, voice input systems have become the most popular tool in imaging departments because their workflows are the most convenient for the implementation of such technology. Current systematic reviews [5–7] have shown that SRT systems are effective in these conditions, and good implementability is explained by large volumes of textual information that radiologists are required to record in protocols.
EVOLUTION OF SPEECH RECOGNITION TECHNOLOGY IN RADIOLOGY
Early years
Medical use of SRTs was first attempted in the 1970s and 1980s. In 1975, a prototype SRT system was described. It could analyze an extremely limited amount of medical vocabulary and terminology [8]. The technology was first tested in diagnostic radiology in 1981 [9]. Beth Israel Hospital started to use it for preparing protocols for X-ray examinations. Initially, local specialists used the coded language information processing (CLIP) system, which is a hierarchical standardized language of medical terms developed by M. Simon and BW Leeming [10]. This language contained specially encoded medical terms. For example, value A was used for the anatomical region, A6 for the lower limb, and A61 for the thigh. Values B, B6, B61, B611, and B612 encoded bones, bones of the lower limbs, femur, lesser trochanter, and grosser trochanter, respectively. By keyboarding various code combinations, a radiologist can prepare a protocol of any complexity and volume [11].
A main disadvantage of those SRT systems is a limited vocabulary (approximately 200 unique medical terms) because of the small random-access memory (RAM). This factor did not allow making a full description of diagnostic examinations. The combined use of STLs with the CLIP system was one of the solutions for the limited RAM.
In 1981, keyboard and voice inputs were compared [9]. The speed and quality of protocol preparation were evaluated for 60 imaging examinations. Consequently, the length of the protocol did not depend on the filling method, which indirectly confirmed the similar complexity of the examinations described. The period of filling out the protocol using voice input was four times longer than the period of the keyboard input. Voice-filled protocols contained an average of 12 recognition errors; whereas protocols prepared using the keyboard had none. This study also described some other limitations of the technology. The first systems could not completely suppress external noise; thus, the quality of medical speech recognition was low, which contributed to errors. The increased period of filling out a medical document was related to the system’s ability to recognize only separately spoken words. A specialist had to pause between words and between codes if the CLIP system was used. This voice-filling method was uncomfortable and unnatural for human communication. Moreover, the voice input system required 3–6 h of preconfiguration and adaptation to the specific speech of the user (specialist).
All these limitations prevented those SRT systems from wider use in healthcare. Thus, medical transcriptionists were highly sought at that time. Nevertheless, all these attempts formed a basis for considering “weak points” of the technology at subsequent stages of development.
The increasing availability of imaging examinations, emergence of computed and magnetic resonance tomographs, and transition from analog to digital media have increased the workload of radiologists and duration of protocol preparation. In the mid-80s, in Western countries, audio transcription centers were opened to solve this problem and optimize human resources. A radiologist taped descriptions of findings identified during the interpretation of diagnostic images using audio recorders. Audio recordings were transferred to the audio transcription center, where medical transcriptionists transcribed the audio recordings and prepared the research protocols in text. The prepared protocols were checked and endorsed by the radiologist. In some cases, they were returned to the transcriptionists for error correction [12]. Dictaphone centers were widely used in foreign healthcare institutions until the 2010s [5, 13].
Some authors compared the efficiency of preparing imaging protocols using medical transcriptionists and SRT. They concluded that the main advantage of a medical transcriptionist is the ability to notice grammatical errors and consider contextual information about the patient. These advantages allow them to correctly understand and adjust audio recordings, even if the quality is poor [14]. However, given the scarcity of medical transcriptionists, printed protocols were often returned to the radiologist only 16 h after dictation [15]. Depending on the capacities of audio transcription centers, transcription of audio recordings took 6–24 h.
Later, medical transcriptionists were no longer needed because of further developments in SRT systems [14]. Despite the lower recognition accuracy of SRTs than medical transcriptionists, SRTs can reduce the monthly economic costs of the radiology department by 81% and significantly reduce the time for preparing examination protocols [5, 13, 16].
In the Russian healthcare system, attempts have also been made to introduce voice recorder centers,2; however, no open-access studies have evaluated their effectiveness. Owing to the lack of such centers in the modern Russian healthcare system, their use was considered inappropriate.
1990s: A new round of innovation
At the end of the 20th century, the amount of memory and vocabulary in SRT systems had increased (up to 19,000 radiology terms). The pre-setting time was reduced to several minutes, and the recognition accuracy was increased. In 1995, the first natural language transcription programs were introduced in the USA, allowing the detection of continuous English speech. Currently, radiologists could dictate at a comfortable conversational pace, without pausing between words. At this stage, these programs were less accurate than systems with separate input [17]. Further technological advances and increased speech recognition accuracy allowed the creation of continuous voice input systems instead of separate input systems.
21ST Century
In Western countries, automated SRTs started to be widely introduced and used in radiology departments in the early 2000s. Foreign studies have compared the speed of voice and keyboard filling of English-language medical records, volume of a medical document prepared, and satisfaction level of specialists. Data showed that technology leads to an increase in document filling speed by 26% and an increase in the volume of protocols. Voice input also allowed optimizing the workflow by reducing the time preparing medical records and improving the quality of protocol content. Specialists showed increased satisfaction from working with such documents [16, 18]. The frequency of errors also decreased, and most errors were related to punctuation [7]. The above factors led to a decrease in the total time for protocol preparation from 16 to 5 h [15]. Studies evaluating the time spent on protocol preparation have revealed that the average number of characters per minute and number and frequency of errors reflect the positive evolution of SRTs and their wider implementation in radiology departments. The percentage of protocols completed within 1 h increased from 26% to 58%. Protocol content became more structured [19].
Costs have also decreased over time. Thus, 5 of 7 cost-evaluating systematic reviews [5] have reported a decrease in costs, and two have reported an increase in costs. Similar results have been obtained in endocrinology and psychiatry, where SRT systems have improved the productivity and efficiency of HCPs [20]. The use of these systems in surgery helped reduce the time for protocol preparation from 4 to 3 days. The number of protocols prepared within 1 day increased from 22% to 37% [21]. From 2019 to the 2020s, foreign studies have concluded that SRTs save HCP time, increases HCP efficiency, and allows them to document more important details when filling out medical papers [22–24]. However, the main barrier to voice input system implementation can be considered a human factor, which is related to HCP resistance to change and fear of new technologies [25].
In 2016, a Microsoft research study showed that SRT systems have an accuracy of 94% and corresponded to the human level [26]. At present, this technology is widely used in medical practice in English-speaking countries, and the implementation level of voice input in radiology departments has reached 85%.3 Currently, the market share of such programs in healthcare is approximately 25% globally.4 Nuance Communications, IBM, and Philips are leaders in speech recognition software development.5
In approximately 45 years, speech recognition has become widespread in healthcare in English-speaking countries. It covered all healthcare levels, from primary care and emergency care to tertiary care clinics. State-of-art medical SRT systems for English-speaking users have an accuracy of up to 99%, can be adapted to different accents, and do not require machine training with the specialist’s voice profile.6
HOW DOES A STATE-OF-THE-ART SPEECH RECOGNITION SYSTEM WORK?
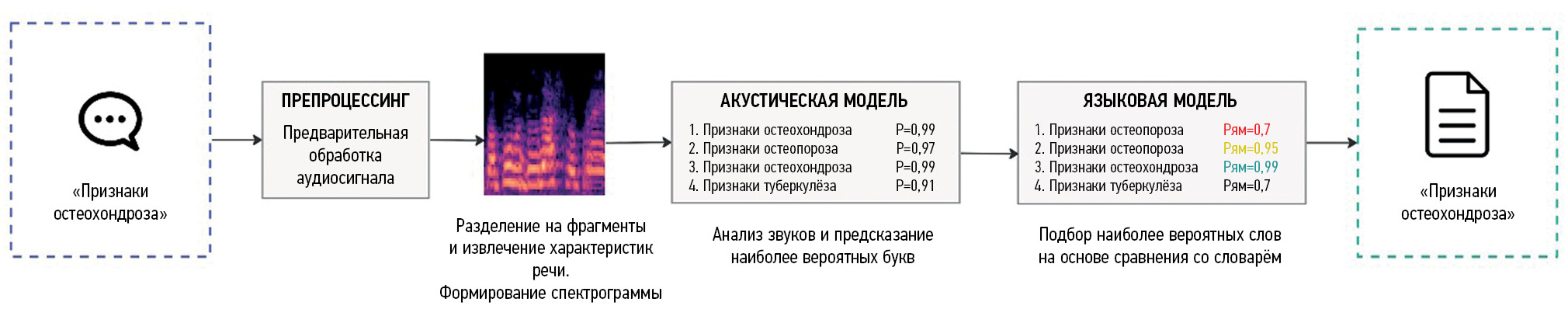
As mentioned earlier, SRT involves translating human speech into text using a computer. Modern voice input systems use artificial intelligence (AI) algorithms that can significantly improve the quality and speed of user speech recognition [27]. The recognition process consists of several stages, with their characteristics (Fig. 1):
- Receiving an audio signal. Sound recording is the first stage of speech recognition. It can be performed using the built-in microphone in any audio recording device, such as a smartphone. Then, the sound wave is converted into a digital format so that it can be processed by a computer.
- Audio preprocessing. The received audio data are preprocessed to eliminate external background noise and make the user’s speech clearer. This improves the quality of speech recognition.
- Splitting into fragments. The audio file is then split into small fragments of 10–25 ms. This is necessary to optimize audio data analysis. Each fragment is analyzed by the SRT system separately.
- Extraction of speech characteristics. At this stage, speech parameters are calculated, including frequency, duration, and amplitude of sounds. They are used to identify phonemes that make up spoken words.
- Comparison with recognition models. Phonemes are matched using acoustic models that are trained on many speech samples. These models can use various techniques including Hidden Markov models, neural networks, and other machine-learning algorithms [28–30].
- Composition of words and text. The language model combines phonemes into words and phrases and then into full text. This text may require additional processing to correct spelling errors and other inaccuracies.
- Inserting the generated text. This is the final stage. The generated text is inserted into the medical document. Considering that speech recognition systems have not yet reached 100% accuracy, in some cases, the radiologist should manually adjust the recognized text.

Fig. 1. A simplified scheme of the operation of a classical speech recognition system. An algorithm for recognizing the “signs of osteochondrosis” phrase is presented.
To enable the system to recognize sounds regardless of sex, age, and intonation of the dictator and convert them into letters with greater accuracy, acoustic and language models use AI modules. Developers train neural networks on a dataset. The dataset includes various audio recordings and text examples. After receiving a voice signal, the neural network searches for a match in the database. The neural network continues its learning during the use and creates new combinations of “sound–letter” pairs, which makes it more likely to reproduce the intended text without spelling errors. During the learning process, the computer recognizes the most important features of the pronunciation of phonemes and records the received data as a user profile [31].7
Recently, the so-called end-to-end approaches to building SRT systems have become widespread. End-to-end approaches in SRT are methods of automatic processing of all speech signals, without performing separate processing steps such as feature extraction and speech recognition model generation [32]. Deep learning is one of the most popular end-to-end approaches. In this case, the neural network is trained directly on raw audio data without preprocessing [32]. Recurrent neural networks or convolutional neural networks are other examples of end-to-end approaches for speech recognition. In this case, the neural network is trained on the input signal and output text using the supervised learning technique [32].
End-to-end approaches can provide higher recognition accuracy because the neural network is trained using all speech information. However, these approaches can be more difficult to implement and require more training data [33].
RUSSIAN EXPERIENCE IN THE USE OF SPEECH RECOGNITION TECHNOLOGY IN RADIOLOGY
The first speech recognition systems for the Russian language appeared in the mid-2000s [34, 35]; however, the use of a general colloquial vocabulary did not allow the use of such systems in medical practice. The development of voice input systems that allows transcribing Russian speech with medical terms took several years [36]. The active development of SRTs was started only in the later 2010s. Such a delay was associated with difficulties in recognizing Russian speech.
The Russian language has a more complex structure of word formation than English because it is a synthetic language with many word forms. To recognize words, a larger vocabulary must be used; however, this slows down system performance [37]. For example, modern SRT systems for English-speaking users use a dictionary containing up to 300,000 words and terms, and for the Russian language, the vocabulary can contain more than 5 million words, word forms, and phrases [33, 38, 39]. In addition, most forms of the same word differ only in endings, which are often vaguely pronounced by users. This leads to an error in recognizing the entire phrase and the need to correct the final document. The Russian language has more options for sentence arrangement, whereas the English language uses strict grammatical constructions. This makes it difficult to create language models of the SRT system and reduces work accuracy.
In Russia, the Speech Technology Center Group (STC) is the leading developer of voice input systems for healthcare.8 The first study of the effectiveness of SRTs in radiology departments was conducted in 2020 in seven city clinics of the Moscow Department of Health using the early version of Voice2Med voice input system (STC Group) with a recognition accuracy of 93%. The study compared the speed of completing medical records using keyboard input and an SRT system. Radiologists filled out protocols of computed and magnetic resonance imaging examinations. The time study showed that the average period of describing one examination using keyboard input was 10 min 15 s, and for an SRT system, it was 8 min 2 s. At the current stage of development, the accuracy of recognition of medical terms in Russian has reached 98%. This became possible thanks to preparing a vocabulary of medical terms, based on 2.5 million imaging protocols, and analyzing feedback from radiologists9 (Fig. 2).

Fig. 2. Workplace of a radiologist at the Moscow Reference Center for Radiation Diagnostics, equipped with a speech recognition system. The process of filling medical records.
In 2022, a survey of radiologists showed that 62.8% of the respondents noted an increase in their efficiency when using an SRT system. Most specialists who use voice input routinely rate the quality of recognition of radiological terms as good or excellent. Respondents note that when extraneous speech was recognized, the endings of words were recognized incorrectly. Moreover, the quality of recognition can be negatively affected by external background noise (working diagnostic equipment and communication of medical personnel with a patient or with colleagues) and low-quality sound recording devices. Important factors in new technology loyalty were the age of HCPs and their interest in innovation. Young professionals are more open to technology, and professionals aged 30–40 years are also more likely to use voice input systems in their work. Surveys showed a positive trend in the attitude of radiologists to SRTs within 2 years from the launch [40].
OPPORTUNITIES FOR THE DEVELOPMENT OF SPEECH RECOGNITION TECHNOLOGY
Improvements in recognition accuracy will further reduce the preparation time of electronic medical records. One of the main tasks facing SRT system developers is to ensure high accuracy of speech analysis in difficult acoustic conditions, when the recording contains numerous noise or voices. As already mentioned, owing to some special characteristics of the Russian language, recognizing word endings become one of the most difficult tasks. Therefore, for Russian SRT systems, a language model that can predict and match words in sentences with high accuracy is needed.
The integration of voice input programs with medical information systems will allow remote filling of structured electronic medical records. As the system is developing, it cannot only recognize HCP phrases but also understand in which section of the medical record the recognized text should be placed. These functions will allow ultrasound diagnostic specialists, pathologists, endoscopists, and surgeons to fill out medical records directly during the medical intervention, not later, and this will significantly affect the quality of documents and the speed of their preparation.
SRT also has great potential in standardizing and unifying the vocabulary used in preparing medical records, including radiological protocols. Currently, no single list of terms has described the same pathological condition in radiology [41]. Even two radiologists working in the same department may use different synonyms to describe the same finding when preparing protocols. Some papers noted that the use of structured and standardized protocols with unified terms simplifies the perception of the necessary information by both other radiologists and other specialists [42–44].
To date, some researchers have attempted to develop a thesaurus to standardize the description of abnormal changes detected in computed tomography. A thesaurus contains 120 Russian radiological terms and examples of their description [45]. However, the development of a thesaurus is a complex task requiring consistent terminology agreed by numerous specialists and the radiology community.
CONCLUSION
The literature review provides a brief historical background on the development of SRTs in radiology departments, describes their evolution in detail, and evaluates the advantages and disadvantages of SRT based on literature data. Special attention is paid to the use of SRTs in Russian radiology departments. Some studies have demonstrated a significant improvement in the accuracy of recognition of Russian medical terms. In the future, the use of such technologies can reduce the preparation period of medical records to allow spending more time communicating with patients and analyzing their medical histories. This opens new opportunities for personalized healthcare development. However, errors remain in ending recognition and word agreement in a sentence, and specialists must spend more time correcting them. In the future, new AI algorithms can solve these problems.
Some studies have demonstrated the positive attitude of radiologists to SRT systems, which is manifested in their more frequent use in their work. This technology should be further developed in the Russian healthcare sector because pilot national and well-established foreign projects indicate positive changes. Further improving the accuracy of medical term recognition will attract even more SRT supporters among HCPs.
ADDITIONAL INFORMATION
Funding source. This article was prepared by a group of authors as a part of the research and development effort titled “Theoretical and methodological framework for digital transformation in radiology” (USIS No. 123031400118-0) in accordance with the Order No. 1196 dated December 21, 2022 “On approval of state assignments funded by means of allocations from the budget of the city of Moscow to the state budgetary (autonomous) institutions subordinate to the Moscow Health Care Department, for 2023 and the planned period of 2024 and 2025” issued by the Moscow Health Care Department.
Competing interests. The authors declare that they have no competing interests.
Authors’ contribution. All authors made a substantial contribution to the conception of the work, acquisition, analysis, interpretation of data for the work, drafting and revising the work, final approval of the version to be published and agree to be accountable for all aspects of the work. N. Kudryavtsev — concept and design of the paper, text writing, approval of the final version of the paper; K. Bardasova — data collection and analysis; A. Khoruzhaya — data interpretation, text editing.
1 Official website of the Moscow Mayor [Web]. The voice assistant will collect patient complaints by phone before a clinic appointment. Available from: https://www.mos.ru/news/item/89302073/.
2 Official site of State Budgetary Healthcare Institution "Infectious Clinical Hospital No. 1 of Moscow Health Department" [Internet]. History of the Hospital, Available from: https://ikb1.ru/about/.
3 Reaction Data [Web]. Speech Rec in Radiology-State of the Market. 2019 [cited 2019 Dec 23]. Available from: https://www.reactiondata.com/report/speech-recognition-in-radiology-state-of-the-market/.
4 Grand View Research [Web]. Voice And Speech Recognition Market Size Report, 2030. Available from: https://www.grandviewresearch.com/industry-analysis/voice-recognition-market.
5 Nuance Communications. Healthcare Clinical Documentation AI Solutions & Services for the NHS (https://www.nuance.com/en-gb/healthcare.html); Philips. Healthcare--Philips (https://www.dictation.philips.com/gb/industries/industry/healthcare-professionals/); IBM. Watson Speech to Text (https://www.ibm.com/cloud/watson-speech-to-text).
6 Nuance Communications [Internet]. Dragon Medical One--#1 Clinical Documentation Companion. Available from: https://www.nuance.com/healthcare/provider-solutions/speech-recognition/dragon-medical-one.html.
7 Cloud.mts.ru [Internet]. Speech recognition technology and its role for business. Available from: https://cloud.mts.ru/cloud-thinking/blog/tekhnologiya-raspoznavaniya-rechi/.
8 Speech Technology Center Group [Internet]. Speech synthesis and recognition, recording and analysis, face and voice identification. Available from: http://www.speechpro.ru/.
9 Speech Technology Center Group [Internet]. Voice2Med: Program for voice filling of medical records. Available from: https://www.speechpro.ru/product/programmy-dlya-raspoznavaniya-rechi-v-tekst/voice2med.
About the authors
Nikita D. Kudryavtsev
Moscow Center for Diagnostics and Telemedicine
Email: KudryavtsevND@zdrav.mos.ru
ORCID iD: 0000-0003-4203-0630
SPIN-code: 1125-8637
Russian Federation, Moscow
Kristina A. Bardasova
Ural State Medical University
Email: bardasovakris@mail.ru
ORCID iD: 0009-0002-4310-1357
SPIN-code: 1156-7627
Russian Federation, Ekaterinburg
Anna N. Khoruzhaya
Moscow Center for Diagnostics and Telemedicine
Author for correspondence.
Email: KhoruzhayaAN@zdrav.mos.ru
ORCID iD: 0000-0003-4857-5404
SPIN-code: 7948-6427
Russian Federation, Moscow
References
- Vechorko VI. Distribution of working time at an outpatient appointment of a district therapist with a nurse in a polyclinic in Moscow (photochronometric observation). Social Aspects Public Health. 2016;(6):4. (In Russ).
- Kaplieva OV, Marega LA, Vorobyeva LP. Timekeeping of working hours of doctors of the children’s consultative and diagnostic department. Far Eastern Med J. 2018;(4):72–76. (In Russ).
- Ryabchikov IV, Zagafarov RR, Mukhina VV, et al. Distribution of the traumatologist-orthopaedician’s working time with outpatients. Моscоw Sur J. 2018;(6):38–43. (In Russ). doi: 10.17238/issn2072-3180.2018.6.38-43
- Kudryavtsev ND, Sergunova KA, Ivanova GV, et al. Evaluation of the effectiveness of the implementation of speech recognition technology for the preparation of radiological protocols. VIT. 2020;6(S1):58–64. (In Russ). doi: 10.37690/1811-0193-2020-S1-58-64
- Blackley SV, Huynh J, Wang L, et al. Speech recognition for clinical documentation from 1990 to 2018: A systematic review. J Am Med Inf Association. 2019;26(4):324–338. doi: 10.1093/jamia/ocy179
- Motyer RE, Liddy S, Torreggiani WC, Buckley O. Frequency and analysis of non-clinical errors made in radiology reports using the National Integrated Medical Imaging System voice recognition dictation software. Ir J Med Sci. 2016;185(4):921–927. doi: 10.1007/s11845-016-1507-6
- Hodgson T, Coiera E. Risks and benefits of speech recognition for clinical documentation: A systematic review. J Am Med Inf Association. 2016;23(e1):e169–e179. doi: 10.1093/jamia/ocv152
- Itakura F. Minimum prediction residual principle applied to speech recognition. IEEE Trans Acoust Speech Signal Process. 1975;23(1):67–72. doi: 10.1109/TASSP.1975.1162641
- Leeming W, Porter D, Jackson JD, et al. Computerized radiologic reporting with voice data-entry. Radiology. 1981;138(3):585–588. doi: 10.1148/radiology.138.3.7465833
- Simon M, Leeming BW, Bleich HL, et al. Computerized radiology reporting using coded language. Radiology. 1974;113(2):343–349. doi: 10.1148/113.2.343
- Vogel M, Kaisers W, Wassmuth R, Mayatepek E. Analysis of documentation speed using web-based medical speech recognition technology: Randomized controlled trial. J Med Internet Res. 2015;17(11):e247. doi: 10.2196/jmir.5072
- Ramaswamy MR, Chaljub G, Esch O, et al. Continuous speech recognition in MR imaging reporting. Am J Roentgenol. 2000;174(3):617–622. doi: 10.2214/ajr.174.3.1740617
- Poder TG, Fisette JF, Déry V. Speech recognition for medical dictation: Overview in quebec and systematic review. J Med Systems. 2018;42(5):89. doi: 10.1007/s10916-018-0947-0
- Sankaranarayanan B, David G, Vishwanath KR, et al. Would technology obliterate medical transcription? In: Proceedings of the 2017 ACM SIGMIS Conference on Computers and People Research. New York, NY, USA: ACM; 2017. P. 97–104. doi: 10.1145/3084381.3084414
- Houston JD, Rupp FW. Experience with implementation of a radiology speech recognition system. J Digital Imaging. 2000;13(3):124–128. doi: 10.1007/BF03168385
- Saxena K, Diamond R, Conant RF, et al. Provider adoption of speech recognition and its impact on satisfaction, documentation quality, efficiency, and cost in an inpatient EHR. AMIA Jt Summits Transl Sci Proc. 2018;2017:186–195.
- Schwartz LH, Kijewski P, Hertogen H, et al. Voice recognition in radiology reporting. Am J Roentgenol. 1997;169(1):27–29. doi: 10.2214/ajr.169.1.9207496
- Vogel M, Kaisers W, Wassmuth R, Mayatepek E. Analysis of documentation speed using web-based medical speech recognition technology: Randomized controlled trial. J Med Int Research. 2015;17(11):e247. doi: 10.2196/jmir.5072
- Hammana I, Lepanto L, Poder T, et al. Speech recognition in the radiology department: A systematic review. Health Inf Manag. 2015;44(2):4–10. doi: 10.1177/183335831504400201
- Mohr DN, Turner DW, Pond GR, et al. speech recognition as a transcription aid: A randomized comparison with standard transcription. J Am Med Inf Association. 2003;10(1):85–93. doi: 10.1197/jamia.m1130
- Singh M, Pal TR. Voice recognition technology implementation in surgical pathology: Advantages and limitations. Arch Pathol Laboratory Med. 2011;135(11):1476–1481. doi: 10.5858/arpa.2010-0714-OA
- Goss FR, Blackley SV, Ortega CA, et al. A clinician survey of using speech recognition for clinical documentation in the electronic health record. Int J Med Inf. 2019;(130):103938. doi: 10.1016/j.ijmedinf.2019.07.017
- Blackley SV, Schubert VD, Goss FR, et al. Physician use of speech recognition versus typing in clinical documentation: A controlled observational study. Int J Med Inform. 2020;(141):104178. doi: 10.1016/j.ijmedinf.2020.104178
- Yang L, Ene IC, Belaghi RA, et al. Stakeholders’ perspectives on the future of artificial intelligence in radiology: A scoping review. Eur Radiol. 2022;32(3):1477–1495. doi: 10.1007/s00330-021-08214-z
- European Society of Radiology (ESR). Impact of artificial intelligence on radiology: A EuroAIM survey among members of the European Society of Radiology. Insights Imaging. 2019;10(1):105. doi: 10.1186/s13244-019-0798-3
- Szymański P, Żelasko P, Morzyet M, et al. WER we are and WER we think we are. arXiv. arXiv:2010.03432.2020. doi: 10.48550/arXiv.2010.03432
- Li J. Recent advances in end-to-end automatic speech recognition. arXiv. arXiv:2111.01690.2022. doi: 10.48550/arXiv.2111.01690
- Juang BH, Rabiner LR. Hidden markov models for speech recognition. Technometrics. 1991;33(3):251–272.
- Graves A, Mohamed A, Hinton G. Speech recognition with deep recurrent neural networks In: 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver, BC, Canada: IEEE; 2013. P. 6645–6649. doi: 10.48550/arXiv.1303.5778
- Deng L, Li X. Machine learning paradigms for speech recognition: An overview. IEEE Trans Audio Speech Lang Process. 2013;21(5):1060–1089.
- Kazachkin AE. Speech recognition methods, modern speech technologies. Young Scientist. 2019;(39):6–8. (In Russ).
- Kamath U, Liu J, Whitaker J. Deep learning for NLP and speech recognition. Cham: Springer International Publishing; 2019. 621 р.
- Wang D, Wang X, Lv S. An overview of end-to-end automatic speech recognition. Symmetry. 2019;11(8):1018. doi: 10.3390/sym11081018
- Zhozhikashvili VA, Farkhadov MP, Petukhova NV, Zhozhikashvili AV. The first voice recognition applications in Russian language for use in The Interactive Information Systems. In: Speech and Computer. Saint-Petersburg, SPECOM; 2004. Р. 304–307. (In Russ).
- Karpov AA, Ronzhin AA, Li IV. SIRIUS system of dictoron-independent recognition of the merged Russian speech. Izvestia Southern Federal University. Technical Sci. 2005;54(10):44–54. (In Russ).
- Irzaev MG. The use of voice input of information in medical institutions to fill in electronic charts and patient medical histories. New technologies and techniques in medicine, biology and ecology: Collection of scientific papers. 2013;(3):149–154. (In Russ).
- Vazhenina D, Markov K, Karpov A, et al. State-of-the-art speech recognition technologies for Russian language. In: Proceedings of the 2012 Joint International Conference on Human-Centered Computer Environments. Aizu-Wakamatsu Japan: ACM; 2012. P. 59–63. doi: 10.1145/2160749.2160763
- Kamvar M, Chelba C. Optimal size, freshness and time-frame for voice search vocabulary. arXiv. arXiv:1210.8436.2012.
- Kipyatkova IS, Karpov AA. An analytical survey of large vocabulary Russian speech recognition systems. SPIIRAS Proceedings. 2014;1(12):7. (In Russ). doi: 10.15622/sp.12.1
- Kudryavtsev ND, Semenov DS, Kozhikhina DD, Vladzymyrskyy AV. Speech recognition technology: Results of a survey of radiologists at the Moscow reference center for diagnostic radiology. Healthcare Management. 2022;8(3):95–104. (In Russ). doi: 10.33029/2411-8621-2022-8-3-95-104
- Sinitsyn VE, Komarova MA, Mershina EA. Protocol of radiological description: Past, present, future. Bulletin Radiology Radiology. 2014;(3):35–40. (In Russ).
- Sobez LM, Kim SH, Angstwurm M, et al. Creating high-quality radiology reports in foreign languages through multilingual structured reporting. Eur Radiol. 2019;29(11):6038–6048. doi: 10.1007/s00330-019-06206-8
- Ganeshan D, Duong PA, Probyn L, et al. Structured reporting in radiology. Academic Radiology. 2018;25(1):66–73. doi: 10.1016/j.acra.2017.08.005
- Dos Santos PD, Hempel JM, Mildenberger P, et al. Structured reporting in clinical routine. Rofo. 2019. Vol. 191, N 01. P. 33–39. doi: 10.1055/a-0636-3851
- Andrianova MG, Kudryavtsev ND, Petryaykin AV. Development of a thesaurus of radiological terms for voice filling of diagnostic research protocols. Digital Diagnostics. 2022;3(S1):21–22. (In Russ). doi: 10.17816/DD105703
Supplementary files

